What is data masking?
Data masking is a technique used in creating structurally similar but inaccurate version of an organization's data that can be used for purposes such as software testing and training.
The purpose data masking is to protect the actual data while providing a working data substitute for occasions where the real data is not required. For example, if a development or testing service is outsourced and we need to provide the employee data to developers outside the organization.
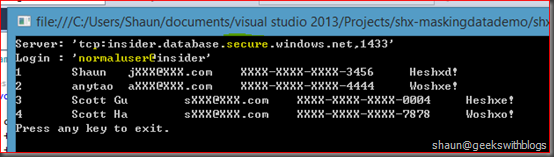
In the wake of compliance enactment, most organizations are no longer comfortable exposing real data. Data Masking substitutes original data with randomized data using various techniques like data shuffling, substitution and masking out. one thing need to ensure that the altered data should maintain the format of the original data. For eg: if the date format in the original data is DD/MM/YYYY then the altered date should also follow the same format.
Why is data masking important?
Various data protection standards and regulations demands protection of personally identifiable information, or PII, and protected health information and keep it confidential. Below Indian DPDP(Data Protection and Data Privacy) laws demand the Protection of PII
- IT Act, 2000
- Digital Personal Data Protection Act, 2023
These regulations and standards play an important role in ensuring appropriate data protection and prevention of unauthorized access of such data. However, it creates challenges for companies that want to analyze or share their data with others. Data masking reduces the risks of critical data being exposed and lets enterprises comply with various standards and regulations while handling their vital information.
Data masking techniques
Various data management techniques can be used to mask PII and other private and sensitive data. Following are the data masking techniques commonly used:
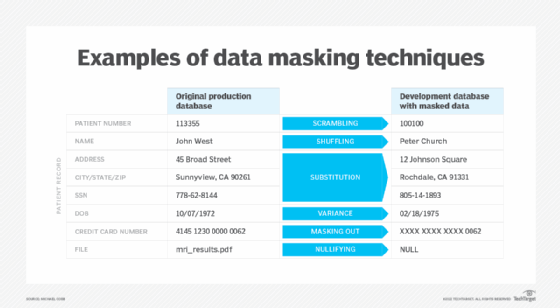
Scrambling
It reorder alphanumeric characters randomly to match the original content. For example, a support ticket number of 5429881 in a production environment could be changed as 8940182 in a test environment via scrambling. Scrambling is easy method of Data masking but it only works on certain data types.
Substitution
In substitution data masking technique; original data is replaced with another value from a set of credible data. Lookup tables are mainly used to provide alternative values. The values must pass certain rule constraints and preserve the original data format. It is harder to implement substitution than scrambling, but it can be applied to several data types and is more secure. For example, credit card numbers can be replaced with numbers that meet the card provider's validation rules.
Shuffling
In the Shuffling technique, Values within a column, such as user surnames, are shuffled to randomly reorder them. For example, if customer surnames are shuffled, the results look accurate but will not reveal any personal information. However, we have to keep shuffling masking algorithm secure so that it cannot be used to reverse the shuffled value to the actual information.
Variance
In this data masking technique, a variance is applied to a number or date field. This approach is mainly used for masking financial and transaction value and date information. The variance algorithm modifies each number or date in a column by a random percentage of its actual value. For instance, a column of employees' salaries could have a variance of plus or minus 10% applied to it. This would provide a reasonable disguise for the data while maintaining the range and distribution of salaries within existing limits.
Masking out
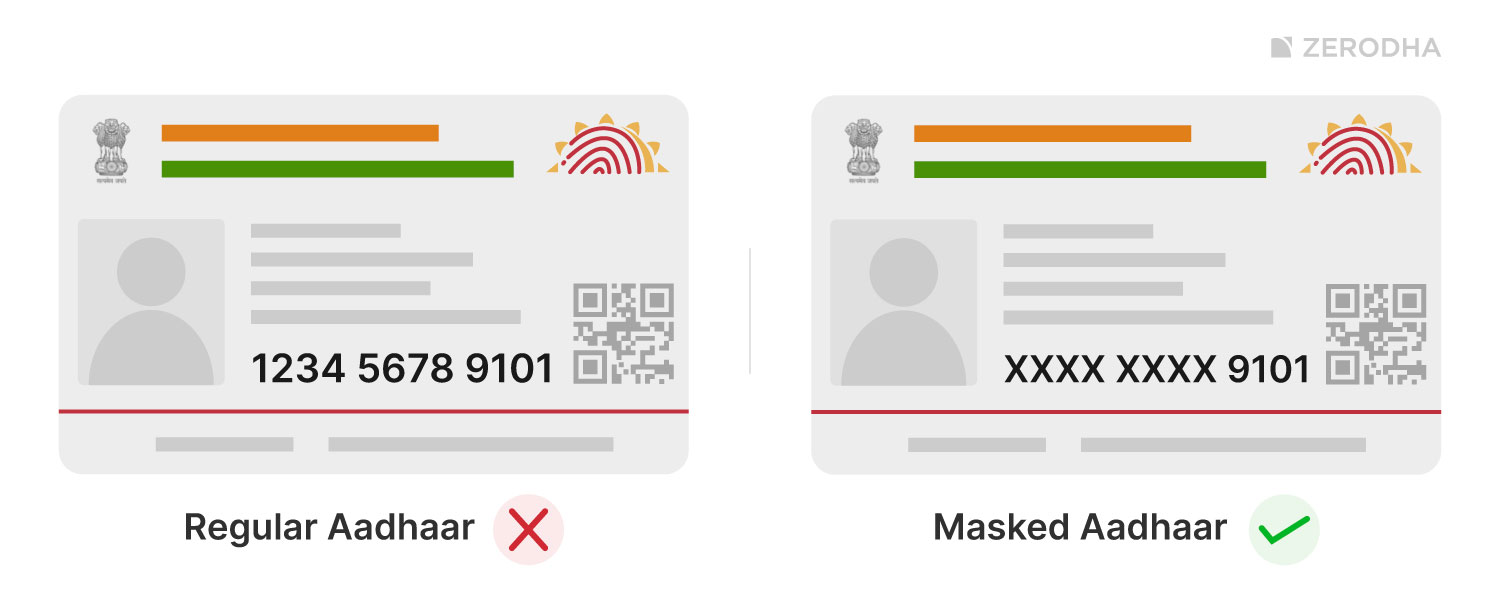
Masking out only scrambles part of a value and is commonly applied to examples like credit card numbers where only the last four digits remain visible. The same technique is used for Masked Adhar card.
Nullifying
In the nullifying technique, it replaces the real values in a data column with a null value, and completely removing the data from view. Although this sort of deletion is simple to implement, the nullified column cannot be used in data queries or analysis. As a result, the integrity and quality of the data can be degraded in a development and testing environments.
Types of data masking
Depending on where and when the data is needed, data masking process can be initiated in different ways . The various types of data masking are the following:
Static data masking
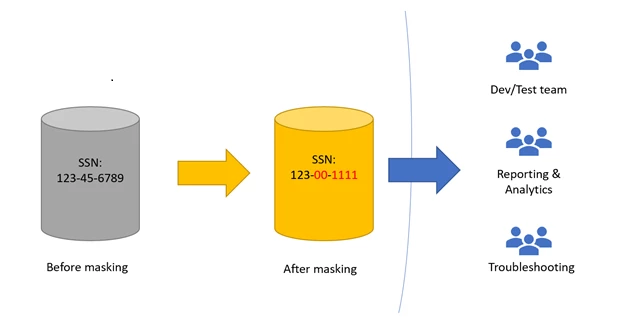
Static data masking creates a separate masked data set from a production database that can be used in non-production environments, such as research, development and testing. The masked data values must generate test and analytical results that exactly same as the original data.
Dynamic data masking
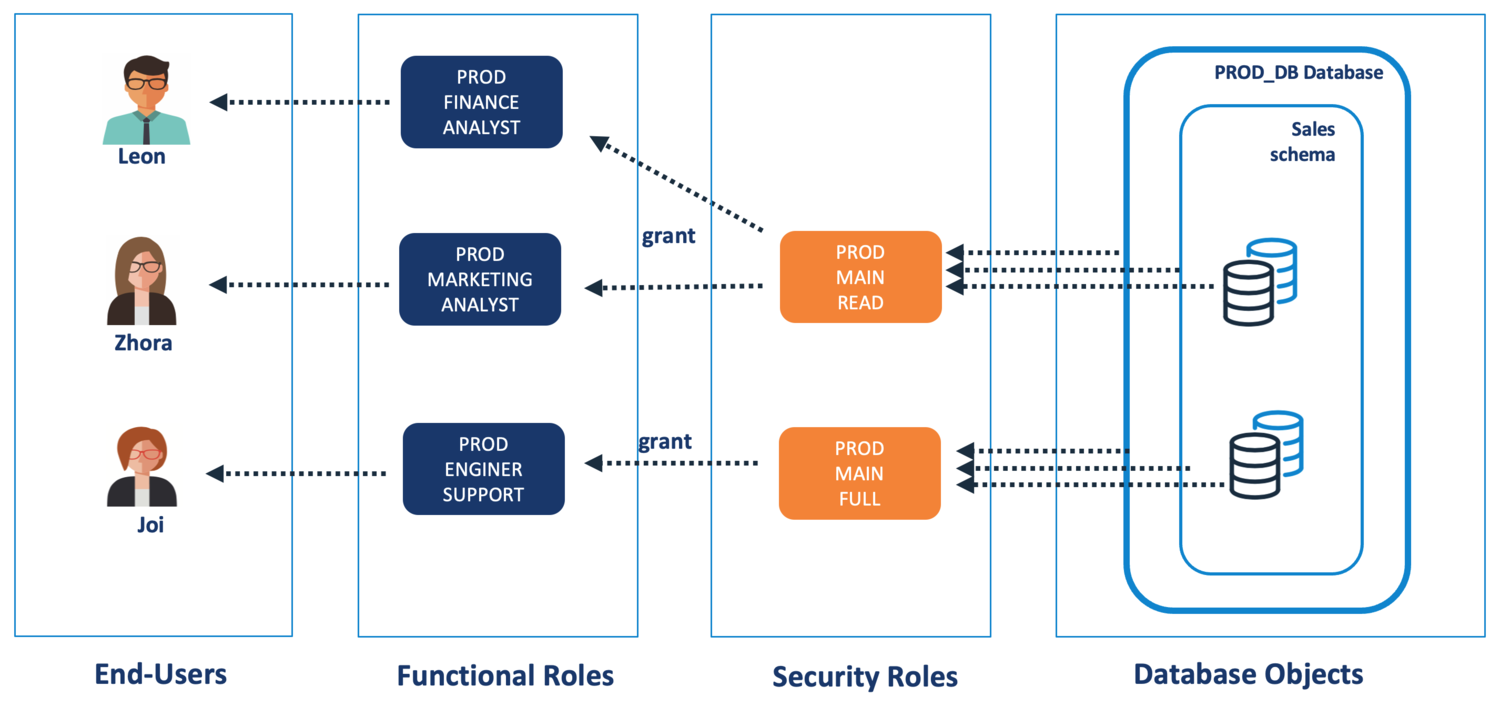
Dynamic data masking allows role-based security, particularly in production environment, when users require real data. In response to a request for data, it dynamically transforms, obscures or blocks access to sensitive information fields in real-time based on the user's role. For example, when a financial call center operator handles a customer query, sensitive fields such as date of birth, Adhar ID number and credit score will be masked unless the operator has the privileges required to view those fields. In response to a request, it avoids the need to store the masked data in a separate database by streaming data from the production environment. incase, if the data is located across multiple systems, masking consistency can be an issue.
On-the-fly data masking
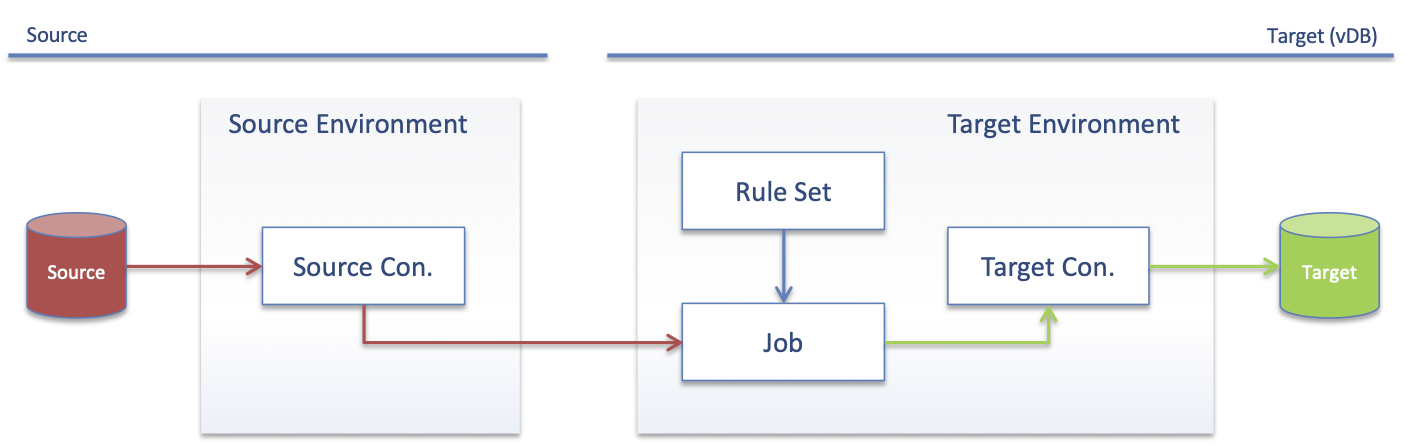
In On-the-fly data masking, it lets the development teams read and mask a small subset of production data directly into a test environment. Data is masked while it is copied from one environment to another, so it is always available in a masked form in the target environment or the target database's transaction log. This way we can avoid delays incurred when a staging environment is used to prepare data. This makes it ideal for continuous software development environments.